
In traditional IP distribution models, the concept of a fixed or static gateway has been the foundation of many broadcast and inter-facility workflows. These can be made redundant to overcome single points of failure, but they are still static and have the normal issues a static gateway has. A centralised point through which all content must pass can appear neat on paper but in reality, it’s a bottleneck. It’s a point of fragility. And it simply doesn’t scale or adapt to the real-time demands of modern live video delivery. A static gateway has a fixed, pre-defined IP address, while a distributed gateway uses multiple devices (or nodes) to act as a gateway, distributing traffic, improving resilience and real-time scalability.
Our distributed gateway architecture replaces rigidity with resilience. It offers scale without fragility, proximity without complexity, and observability without guesswork. In this post, we break down how and why GlobalM’s approach delivers a clear technical advantage over other network gateway architectures.
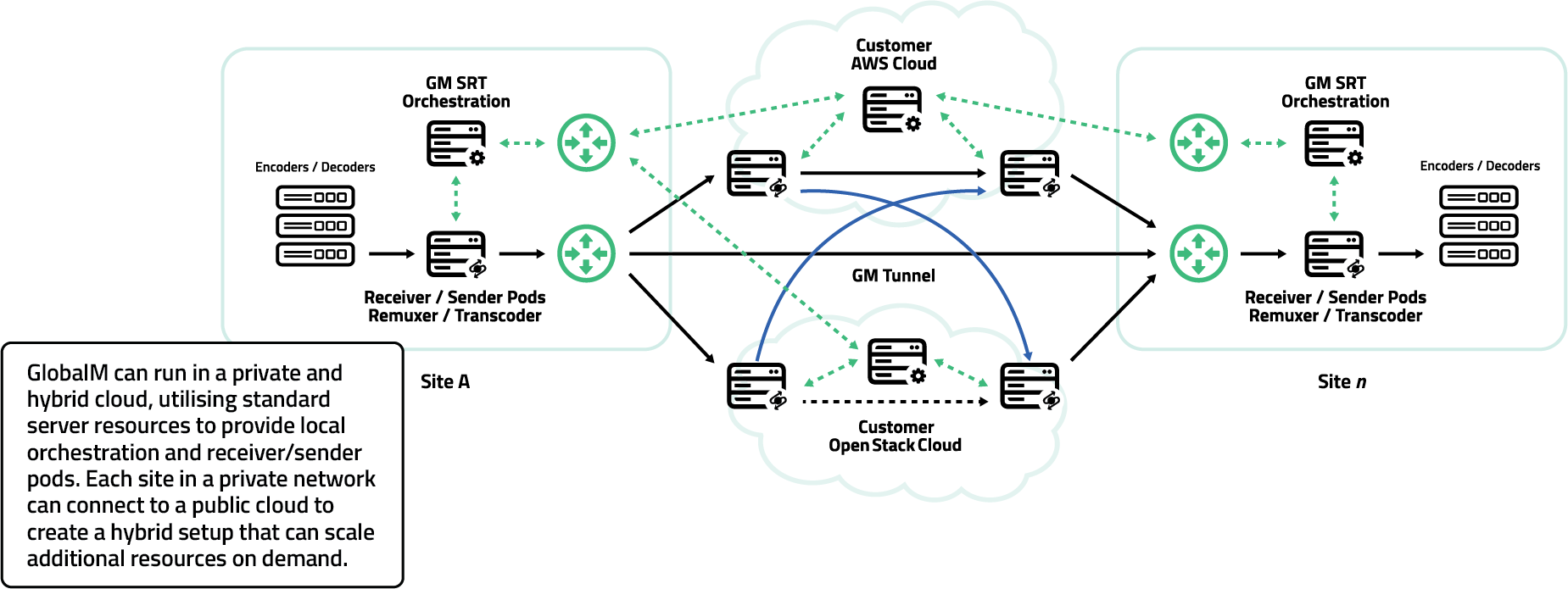
The Role of the Orchestrator
GlobalM’s orchestrator is the automation engine that enables our distributed gateway architecture to function intelligently, efficiently, and at scale. It’s important to clarify this isn’t containerization or container orchestration. Our orchestrator doesn’t manage containers. It manages full systemd based services running on virtual machines or physical infrastructure, with direct control over configuration, lifecycle, and performance.
Multiple orchestrators can operate across a GlobalM designed network, each responsible for provisioning stream sender pods, receiver pods, and transcoding services. These orchestrators automatically determine where services should spin up based on proximity to signal sources, available capacity, and real-time network health. Once spun up, they configure routing, allocate resources, and maintain operational balance across the system.
A pod is a streaming resource that can be either a stream receiver, sender or transcoder. A pod can be a stream receiver for a service in one region and in another region, a pod can be a stream sender for a particular service. A receiver pod can be connected to any number of sender pods at any point in time making a flexible and responsive point to multipoint distribution technology.
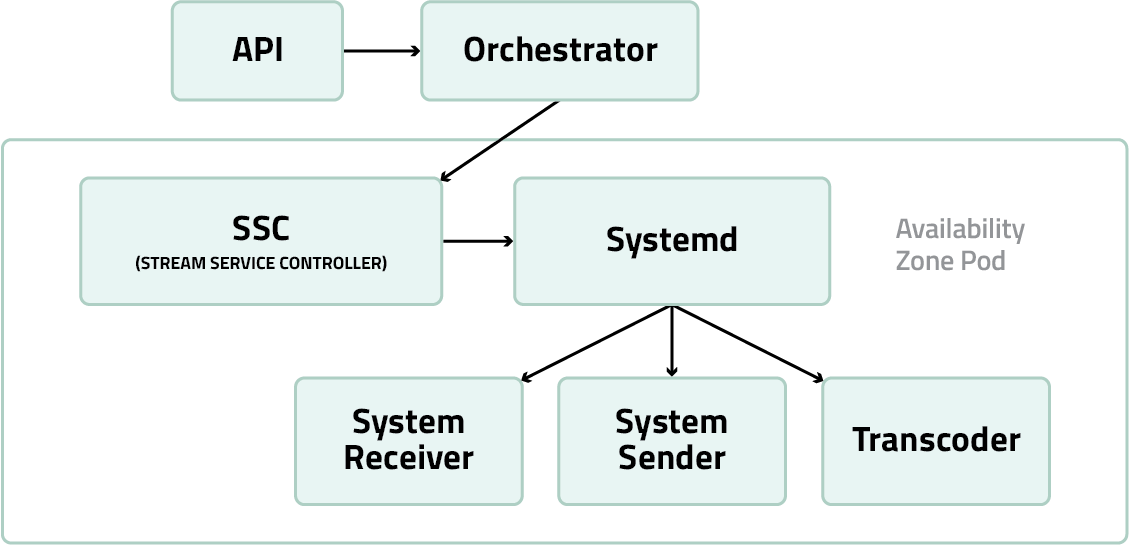
The GlobalM orchestrator speaks with the SSC of the pod. The SSC controls the behavior of the pod and manages the type of service that pod is running within a network transmission as well as routing, load-balancer configuration, processing and monitoring.
Importantly, GlobalM’s orchestrators also integrate with our internal and/or an external scheduling systems (via API). This allows stream services to be scheduled and deployed dynamically based on actual usage windows, rather than left running indefinitely. As a result, we avoid unnecessary compute costs and idle infrastructure. Services spin up just before they’re needed and shut down automatically after the job completes. This is a major advantage over static gateways, which require manual provisioning and persistent uptime regardless of whether content is flowing. And in the case of permanent services, the orchestrator can provision and keep services running until otherwise released.
Operators aren’t logging into hypervisors or triggering deployments manually. The orchestrator handles infrastructure spin-up, configuration, and connection logic end to end, and this can be in multiple different clouds. Redundancy strategies such as SMPTE 2022-7 and seamless switching are also embedded in this automation layer, enabling seamless path switching at the packet level based on the individual redundancy requirements of a transmission.
Because the orchestrator manages stable, systemd based services, rather than volatile containerised jobs, we achieve high reliability, tight control, and a broadcast grade level of predictability. This is automation designed specifically for live IP video, not general purpose cloud computing.
Spawning, Scaling, and the Absence of Bottlenecks
In traditional gateway based IP broadcast networks, there’s always a centralised point of control, a bottleneck, whether physical or virtual. Everything eventually funnels through it. And while that might have worked in the past, it simply doesn’t hold up under the weight of modern demands to react quickly such as during a breaking news event, onboarding last minute rights holders, or scaling a pool feed for large scale live coverage.
GlobalM takes an entirely different approach. Every node in our network, whether it’s acting as a stream receiver, sender, or transcoder, is part of a fully distributed system. There is no fixed gateway. No hardwired control point. That’s by design.
The orchestrator manages multiple pods running on machine instances. Since system resources are managed at the systemd level of the OS kernel, these pods are not containerised. Instead, they use only the specific machine resources they’re allocated for clearly defined tasks like transcoding and stream processing. When a machine instance reaches a predefined resource threshold, the orchestrator can spin up a new instance, either locally or in the cloud, depending on the customer’s deployment configuration.
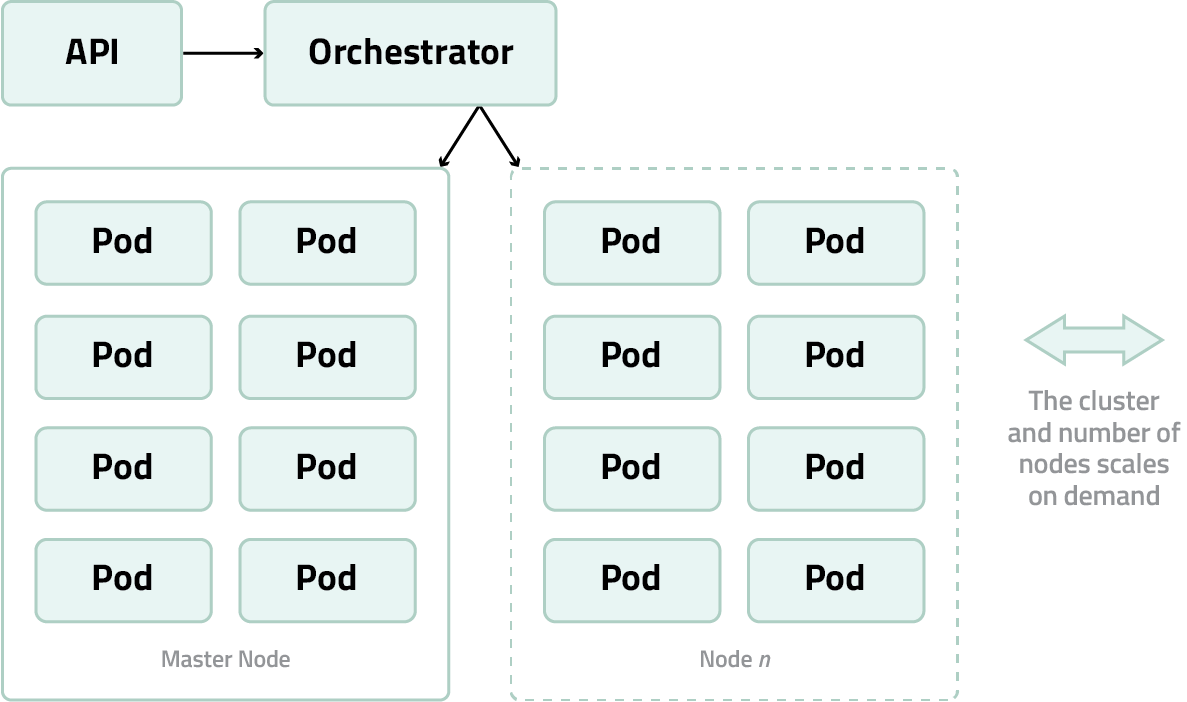
Pods can run on-premises and/or in the cloud based on a customer’s chosen setup. In a hybrid configuration, customers may opt to run a majority of their operations from fixed on-prem infrastructure, keeping routine workloads cost-effective, while cloud-based pods are dynamically added during peak demand. This makes the system ideal for unpredictable surges in traffic or event-driven spikes like sports finals or news coverage.
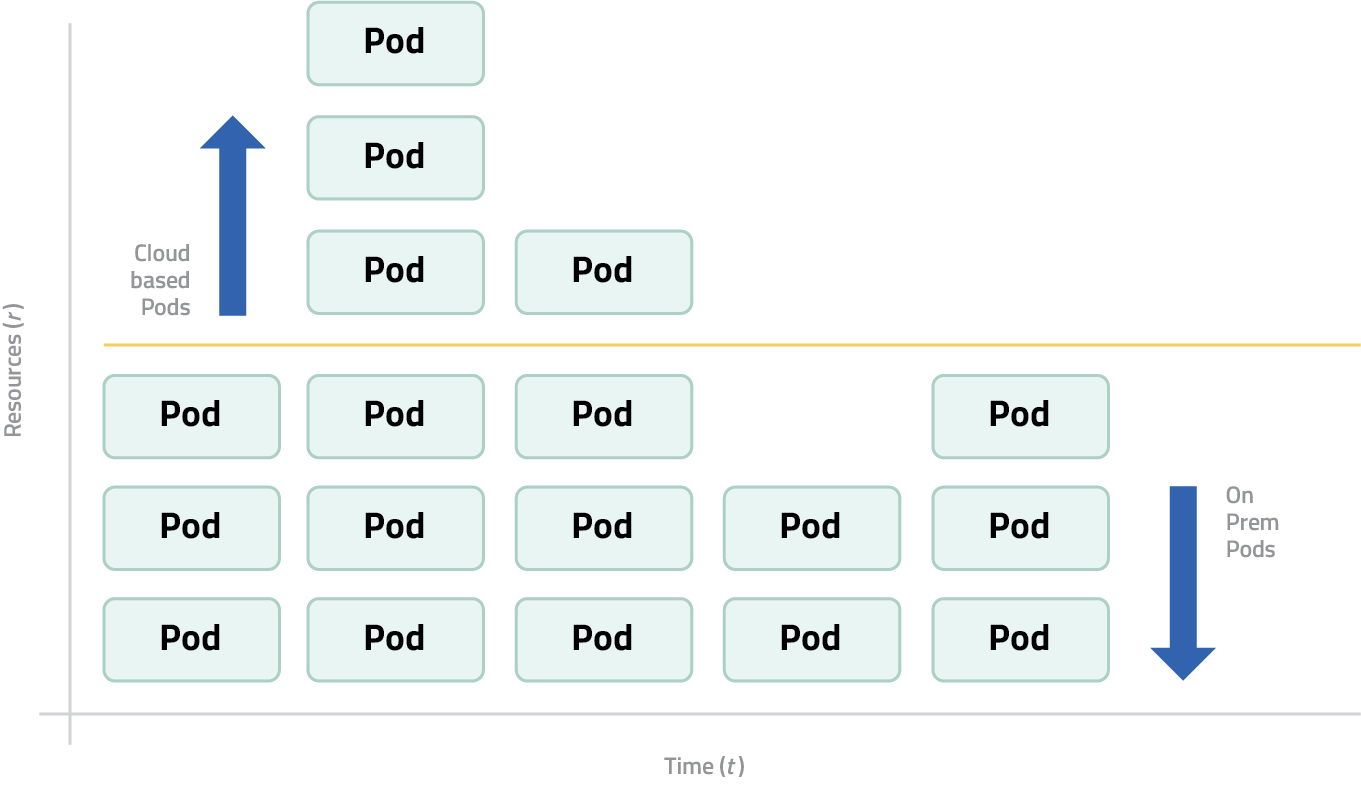
This distributed architecture is what allows us to scale in real time. When traffic increases, there’s no need for manual provisioning or network reconfiguration. The orchestrator spawns new pods automatically, and the network expands without delay.
Compared to static gateway networks, which often struggle to scale quickly and typically require advance planning and over-provisioning, GlobalM’s model is dynamic, responsive, and cost-efficient by design.
Deployment Architecture
Another defining strength of GlobalM’s distributed gateway model is the way we deploy infrastructure. We operate across a mix of different clouds and regions, private networks, and on-prem environments. And unlike containerized systems, our services run as hardened, systemd managed instances.
The orchestrator determines where services spin up, always favouring locations close to the signal source or destination. That minimises hop count, reduces latency, and enhances QoS. Because we’re cloud agnostic, we can adapt our topology around the world without being constrained by a single vendor’s footprint. For network operators, you can run your own private services with a mix of cloud providers, maintaining fixed costs and network for predictable traffic and use cloud to burst for additional occasional use transmissions on an adhoc basis.
This stands in clear contrast to static gateway setups, which rely on fixed infrastructure in a limited set of regions. These systems require signals to be routed through pre-defined locations, often far from where the content is produced or consumed. In contrast, GlobalM’s approach brings the infrastructure to the signal, deploying services dynamically wherever they’re needed most, reducing unnecessary routing and enabling truly global responsiveness.
Retransmission Domains and Latency
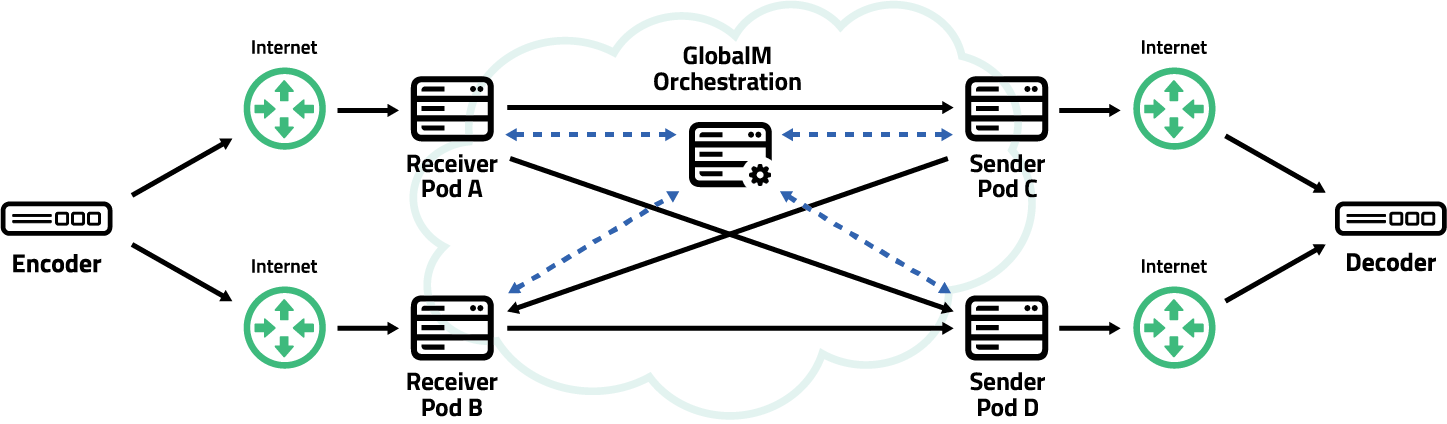
One of the less obvious, but absolutely critical advantages of GlobalM’s distributed gateway architecture lies in how we manage ARQ retransmission. In a traditional fixed gateway setup, any packet loss requires a round trip to a central server, often hundreds or even thousands of kilometres away. That introduces delay, friction, and often frustration, especially in live workflows where every millisecond counts.
By contrast, our architecture defines retransmission domains at the edge. Each stream sender pod and receiver pod communicates with the network core through shorter paths, often staying entirely within a local or regional zone. If a packet needs to be resent, it doesn’t have to travel halfway across the globe and back. It simply bounces between nearby nodes, shaving valuable time off every correction and maintaining a smoother, more resilient stream.
![]()
And here’s where it gets even better. Because retransmissions happen locally, latency drops. And when latency drops, throughput naturally increases. That’s not specific to our network, it’s just how all networks behave. Lower latency equals higher throughput. So, by shrinking retransmission distances, we not only speed up recovery but also boost the overall efficiency of every connection running through the network.
This isn’t just about saving milliseconds, it’s about preserving experience. Whether you’re broadcasting a sport or breaking news, consistency matters. Viewers don’t see dropped packets. They see buffering, break up and glitches. And in a world where attention spans are razor thin, even one stumble is too many.
Real-Time Observability and Monitoring
In live IP video, silence isn’t golden, it’s dangerous. You don’t want to be guessing if a stream is healthy. You want to know instantly, continuously, and in context. That’s why observability isn’t an afterthought in GlobalM’s architecture. It’s built in from the ground up.
Every sender pod, receiver pod, and transcode pod reports real-time metrics back to the orchestrator. Packet loss, packet resends, bitrate, latency, bitrates, network load, it’s all visible. The orchestrator uses this data both to inform decisions and to power our internal dashboards and alarm systems.
In addition to live metrics, we also employ exception monitoring. This means the system doesn’t just report on what’s happening, it actively watches for anomalies and unexpected behaviours. Whether it’s a service dropping below an expected bitrate, a spike in packet loss, or the wrong passphrase entered by a rights holder, our exception monitoring framework flags these conditions immediately and notifies the appropriate systems or operators. This allows us to intervene before an issue becomes a visible failure.
This proactive monitoring approach means that potential issues can be addressed before they impact service quality. Unlike static gateway models, which often detect and respond to faults only after they’ve disrupted delivery, GlobalM’s observability is designed to anticipate and mitigate problems before they become failures.
Security Built for Broadcast
GlobalM’s distributed architecture is also built with strong security principles. Each managed service runs in an isolated environment with strict authentication, per-session encryption, and path-level control. We don’t rely on centralised access points which means there’s no single door to breach.
Streams are encrypted end to end. Sessions are logged and monitored. Access is tightly controlled. And because the architecture is distributed, compromise of any one node doesn’t expose the network as a whole. In the broadcast world, where content is valuable and downtime is reputationally costly, this kind of security posture is essential.
Contribution and Distribution, Handled Together
One final advantage of GlobalM’s model is that we handle both contribution and distribution across the same intelligent mesh. A contributor can send a stream into a regional receiver pod, and that same network can deliver the content to playout, cloud production, OTT platforms, or affiliates without duplicating workflows or infrastructure in formats like HLS, MPEG DASH, SRT, RIST and RTMP.
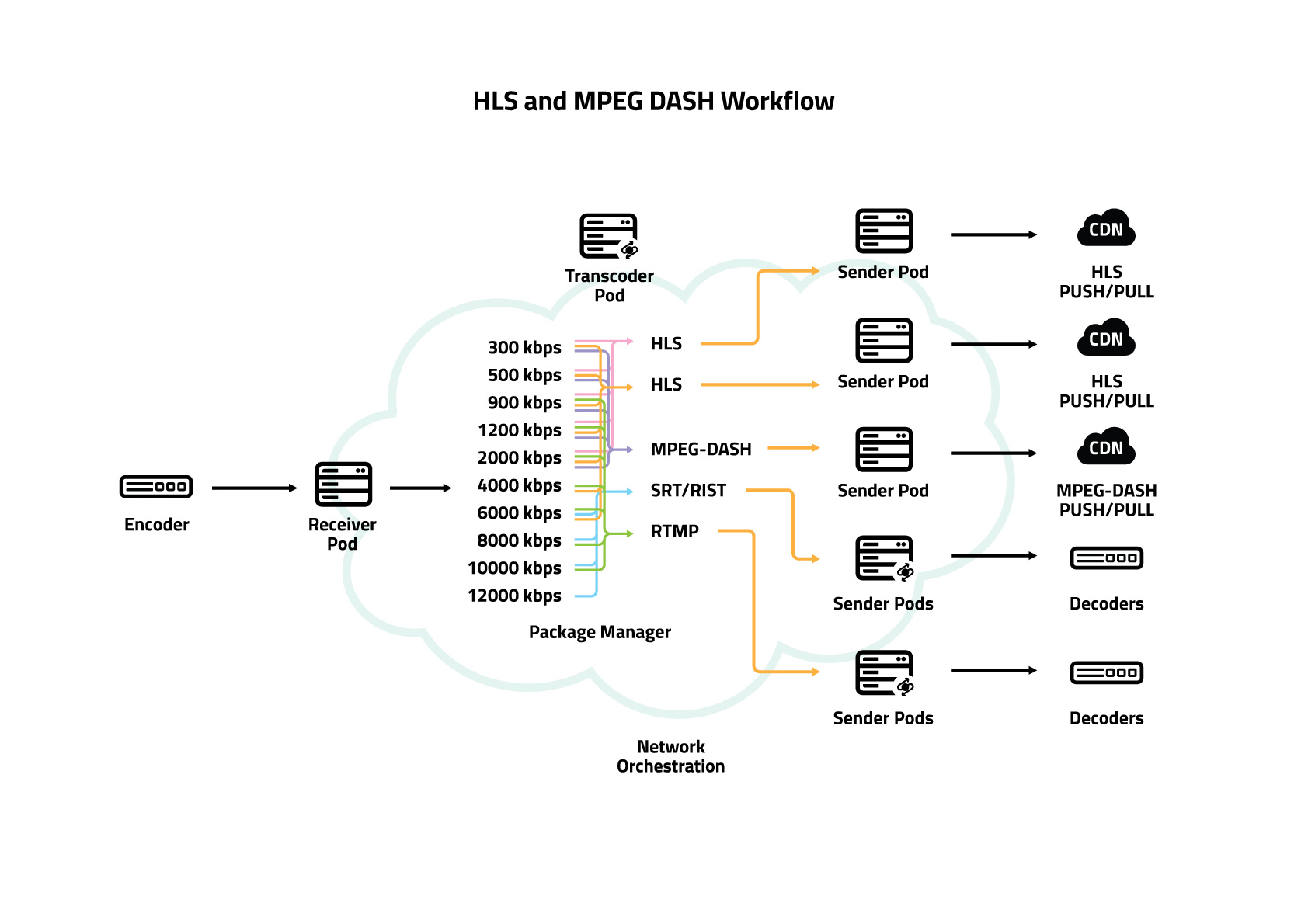
The same stream that gets ingested can be transcoded, replicated, and distributed all through orchestrated connections within the same mesh. No handoffs. No re-ingestion. Just continuity.
Fixed gateways have had their time. But modern IP video, especially live video demands something more adaptable, more resilient, and more intelligent. GlobalM’s distributed gateway model isn’t a tweak to the old way of doing things. It’s a fundamental rethink. And for broadcasters, producers, and network operators looking for scalability, performance, and peace of mind, it’s a rethink worth making.
